유전체 신생아 선별검사(gNBS): 우리 아이의 유전적 위험을 빠르게 확인하고 대처할 수 있는 검사
최근 전 세계적으로 유전체 신생아 선별검사(genomic Newborn Sequencing, gNBS) 연구가 활발하게 진행되고 있습니다. 이는 겉보기에 건강한 신생아에게 잠재적인 유전 질환 위험을 조기에 진단하고 치료할 기회를 제공하는 혁신적인 접근법입니다. 이번 글에서는 gNBS가 무엇인지, 현재 전 세계적으로 어떻게 진행되고 있는지, 그리고 앞으로 나아가야 할 방향에 대해 논문을 바탕으로 자세히 알아보겠습니다.
gNBS(유전체 신생아 선별검사)란 무엇이며, 그 목적은?
gNBS는 신생아 및 소아 유전체 시퀀싱(NBSeq)을 통해 유전 질환의 위험을 조기에 탐지하는 과정입니다.
목적
- 겉보기에 건강한 영아에게 발생할 수 있는 유전 질환의 위험을 조기에 발견합니다.
- 조기 진단 및 개입을 통해 질병의 돌이킬 수 없는 손상을 예방하고 치료 결과를 개선하는 것을 목표로 합니다. 특히, 현재 700개 이상의 유전 질환에 대해 표적 치료나 장기 관리 지침이 존재하여 gNBS에 대한 관심이 더욱 커지고 있습니다.
전 세계 gNBS 프로그램 현황: 누가, 어디서 하고 있나?
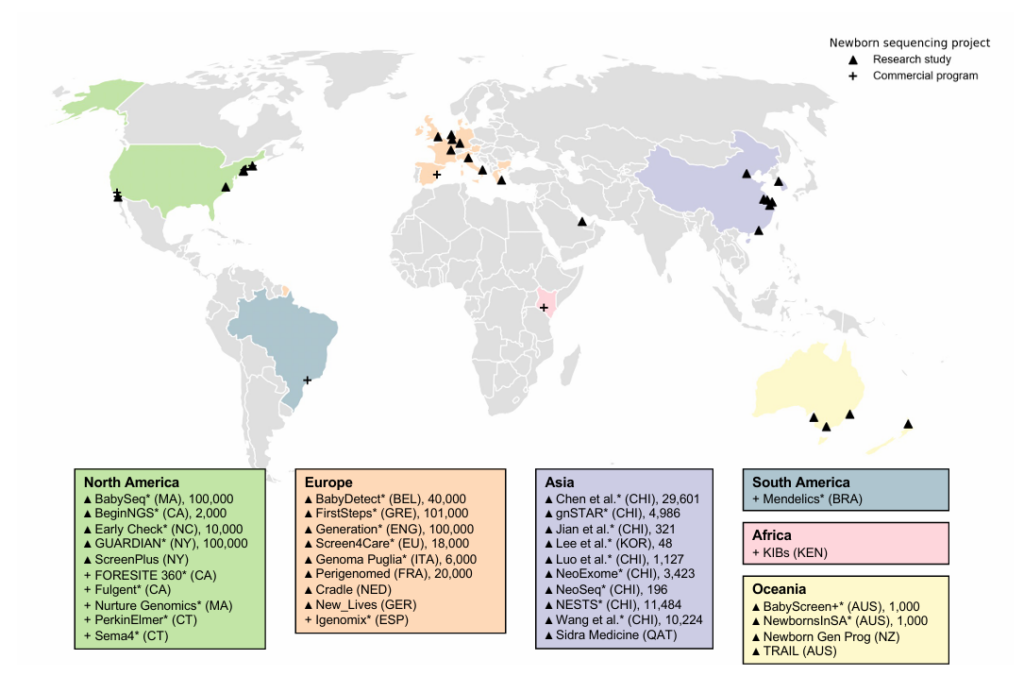
현재 30개 이상의 국제 연구 프로그램 및 상업 회사가 gNBS 접근 방식을 활발하게 탐색하고 있으며, 이들 중 다수는 신생아 시퀀싱 국제 컨소시엄(ICoNS)을 통해 모범 사례를 교환하고 있습니다.
- 총 35개의 연구 및 상업 프로그램이 확인되었으며, 이 중 10개가 북미, 10개가 아시아, 9개가 유럽에 위치하고 있습니다.
- 2024년 9월까지 총 68,628명의 영아를 대상으로 한 9개 연구 프로그램의 결과를 보면, 양성 선별 결과 비율은 1.85%에서 9.43% 사이였으며, 평균적으로는 3.82%였습니다.
출처: Genet Med. 2025 Jul;27(7)
프로그램 간 유전자 목록 비교와 그 차이점
27개 gNBS 프로그램에서 분석 대상으로 포함된 총 4,390개의 유전자를 비교한 결과, 프로그램 간에 상당한 이질성(heterogeneity)이 나타났습니다.
🔍 주요 발견
- 유전자 목록 크기: 프로그램별 분석하는 유전자 수는 134개에서 4,299개까지 광범위하게 분포했습니다 (중앙값 306개).
- 높은 일치도(Concordance) 유전자: 4,390개 유전자 중 80% 이상의 프로그램(27개 중 22개 이상)에서 공통으로 포함된 유전자는 단 74개(1.7%)에 불과했습니다.
- 주요 임상 영역: 대부분의 유전자는 유전성 대사 장애(IMDs, 25.4%), 신경학적(15.5%), 면역학적(11.9%) 장애와 관련이 있었습니다.
- 미국 RUSP의 영향: 프로그램 간에 유전자 포함 여부를 예측하는 가장 강력한 요소는 유전자가 미국 Recommended Uniform Screening Panel(RUSP)에 포함되어 있는지 여부였습니다.
[유전자 목록 포함을 예측하는 요인]
회귀 분석을 통해 유전자 목록 포함과 가장 유의미한 양의 상관관계를 보이는 특성들이 확인되었습니다.
가장 강력한 예측 변수
- RUSP 포함 여부 (코어 조건 74.7%, 보조 조건 60.0% 증가)
- Natural history에 대한 확실한 근거 기반(Evidence Base) (29.5% 증가)
- 치료 효과의 높음 (17.0% 증가)
- 전문가 권장 점수 (80% 이상 전문가 권장 시 43.5% 증가)
다른 중요한 예측 변수
- 높은 침투율(Penetrance), 신생아/영아 발병 시기, 높은 질병 심각도, 치료 수용성 등
gNBS의 미래: 어떤 방향으로 나아가야 하는가?
gNBS 프로그램 간의 상당한 유전자 목록 차이는 일관되고 정보에 기반한 유전자 선택 방법의 필요성을 보여줍니다.
[데이터 기반 접근 방식]
이 연구에서는 부스팅 트리(boosted trees) 기계 학습 모델을 개발하여 유전자 선택을 위한 데이터 기반의 접근 방식을 제시했습니다.
- 모델 특징: 13가지 유전자-질환 특성(RUSP 범주, 임상 영역, 치료 효과 등)을 사용하여 유전자 포함 여부를 예측하며, 높은 정확도(AUC=0.915, R2=84%)를 달성했습니다.
- 활용: 이 모델은 새로운 증거와 지역적 필요에 따라 조정 가능한 유전자 순위 목록을 제공하며, 공중 보건 프로그램이 NBSeq를 도입할 때 유전자를 우선순위화 하는 데 도움을 줄 수 있습니다.
- 간과된 유전자 식별: 이 모델은 현재 소수 프로그램에만 포함되어 있지만 포함 가능성이 높다고 예측되는 유전자들(예: PTPRC, CYBA 등)을 식별하여, 연구자들이 놓쳤을 수 있는 유전자를 찾는 데 유용합니다.
[향후 과제 및 개선 방향]
- 데이터 개선: 향후 연구에서는 부모 및 소아과 의사와 같은 주요 정보 제공자의 관점을 통합하고, 유전자 길이, gnomAD 제약 점수 등 추가적인 생물정보학적 데이터를 포함하여 모델을 개선할 계획입니다.
- 지식 확장: 현재 포함되지 않은 유전자 중 유사한 특성을 공유하는 유전자를 식별하기 위해 지식 그래프(knowledge graph)를 활용할 계획입니다.
- 유연성과 일관성: 궁극적으로 정적인 유전자 목록 대신, 새로운 지식과 치료법의 등장에 따라 업데이트 될 수 있는 동적 순위 시스템을 통해 gNBS의 유전자 선택에 대한 국제적 합의와 일관성을 높이는 데 기여할 것입니다.
gNBS는 유전 질환의 조기 발견을 위한 중요한 전환점이 될 수 있습니다. 분석항목을 선정함에 있어 여전히 정답은 존재하지 않습니다. Sensitivity를 높여 위험 가능성을 최대한 찾자는 “Screening”목적일 수도 있고, Specificity를 높여 임상적으로 actionable한 것만 보자는 “Clinical Utility” 목적이 더 강한 프로그램일 수도 있겠습니다. 최적의 항목은 다양한 프로젝트에서 데이터 주도적 접근 방식으로 접근해가며 쌓이는 정보가 신뢰할 수 있는 스크리닝 전략을 구축하는 데 핵심적인 역할을 할 것으로 기대됩니다.
이 블로그 게시물이 gNBS에 대한 이해를 돕고, 앞으로의 논의에 유용한 자료가 되기를 바랍니다.
3billion 뉴스레터 구독자만을 위한
희귀질환 진단 최신 정보를 받아보세요.

Sookjin Lee
기술 및 시장 통합 전문가 | 글로벌 헬스케어 혁신 유전체 데이터 기반 의료 분야에서 15년 이상 경력을 쌓은 저는 좋은 기술을 시장 요구에 맞춰 영향력 있는 변화를 만들어내는데 주력하고 있습니다. 전문 지식을 시장 눈높이에 맞춰 전달하고, 새로운 시장으로의 확장을 촉진하여 더 나은 삶을 살게 만들고자 합니다.