AI 예측 툴이 희귀질환 진단을 바꾸는 방법: : ACMG PP3 근거 강도와 REVEL, 그리고 3Cnet
요약
- ACMG/AMP 변이 해석 기준 중 PP3/BP4는 missense variant의 in silico 예측 툴을 근거로 삼는 대표적인 기준입니다.
- 2022년 ClinGen 연구(Pejaver et al.)는 13개 예측 툴의 성능을 정량 평가해, 조건이 맞으면 PP3를 supporting이 아닌 moderate 또는 strong까지 부여할 수 있음을 제시했습니다.
- 그 기준에서 REVEL은 PP3 strong + BP4 very strong 양방향 모두 도달 가능한 유일한 툴로 확인됐습니다.
- 3billion은 REVEL을 1순위 기준으로 채택하되, REVEL이 다루지 못하는 영역을 자체 개발 툴 3Cnet으로 보완합니다.
1. 변이 해석의 28가지 기준 중, AI가 가장 빠르게 진화하는 영역
희귀 유전 질환 진단에서 변이를 해석할 때, 임상 유전학자들은 ACMG/AMP 가이드라인이 제시하는 28가지 기준을 종합적으로 검토합니다. 인구 집단 빈도, 변이 유형, 유전 양상, 기능 연구 등 다양한 근거 기준이 존재합니다.
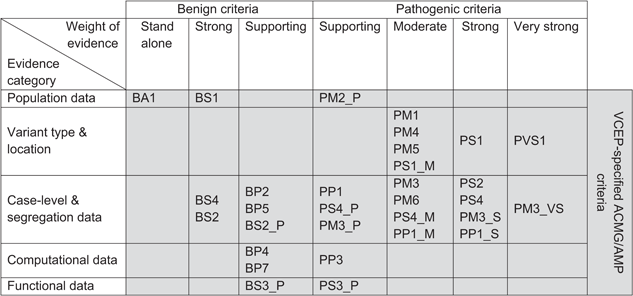
출처: https://onlinelibrary.wiley.com/doi/full/10.1002%2Fhumu.24280
그 중에서 in silico 예측 툴의 결과를 근거로 삼는 기준에는 PP3, BP4, BP7이 있습니다. 이 중 PP3와 BP4는 missense variant의 병원성 예측 툴을 근거로 하며, 이 글에서는 missense pathogenicity prediction 툴이 직접 적용되는 PP3와 BP4에 집중합니다.
- PP3: in silico 예측 툴이 해당 변이가 단백질 기능에 영향을 줄 것으로 예측할 때 적용 (pathogenic 방향 근거)
- BP4: in silico 예측 툴이 해당 변이가 단백질 기능에 영향을 미치지 않을 것으로 예측할 때 적용 (benign 방향 근거)
이 두 기준이 주목받는 이유는 명확합니다. AI와 딥러닝 기술의 발전 속도가 가장 빠르게 반영되는 영역이 바로 여기이기 때문입니다. 기능 실험은 시간이 걸리고, 가족력 정보는 항상 있는 건 아니지만, 전산 예측 툴은 매년 새로운 모델이 등장하며 정확도가 개선되고 있습니다.
2. 과거에는 어떻게 예측 값을 진단에 활용했나 — “여러 툴이 동의하면 supporting 1개”
ACMG/AMP 2015년 가이드라인은 PP3/BP4 적용 방식을 이렇게 정의했습니다.
“여러 in silico 툴이 동일한 변이에 대해 유해성 또는 무해성을 지지하는 경우, supporting 수준의 근거로 인정한다.”
즉, 사용한 툴의 개수나 툴에서 제시하는 점수와 상관없이 PP3는 항상 supporting 근거 1개로 고정이었습니다. 변이를 LP(Likely Pathogenic)로 분류하려면 supporting 근거 여러 개와 다른 stronger 근거들을 조합해야 했기 때문에, PP3 단독으로 분류에 미치는 영향은 제한적이었습니다.
그리고 이 방식에는 실질적인 문제가 있었습니다.
- 서로 다른 툴이라도 훈련 데이터가 겹쳐 독립적인 근거가 아닌 경우가 많았습니다
- SIFT, PolyPhen-2, CADD처럼 오래되고 널리 쓰이는 툴들이 개발자 권장 threshold에서도 PP3 supporting 기준을 충족하지 못한다는 연구 결과도 있었습니다 (Pejaver et al., 2022, Table 3)
- 특히 CADD는 score 20.0 (개발자 권장 threshold)이 PP3가 아닌 BP4 moderate 구간에 해당한다는 충격적인 결과도 나왔습니다
많은 임상 현장에서 CADD를 pathogenicity 근거로 활용해왔던 관행에 의문이 제기된 것입니다.
3. 2022년, ClinGen의 질문 — “툴마다 신뢰도가 다르다면, 점수 구간에 따라 근거 강도도 달라져야 하지 않나?
ClinGen Sequence Variant Interpretation Working Group은 2022년 American Journal of Human Genetics 에 이 문제를 정면으로 다룬 연구를 발표했습니다.
연구팀의 핵심 질문은 이것이었습니다.
“툴의 점수가 충분히 높을 때, PP3를 supporting이 아니라 더 높은 강도로 부여할 수 있지 않을까?”
이를 검증하기 위해 ClinVar 2019 기반의 표준 변이 데이터셋(pathogenic/likely pathogenic 및 benign/likely benign, 11,834개 변이, 1,914개 유전자)을 구축하고, 각 툴의 점수 분포에서 Bayesian 확률 프레임워크를 적용해 likelihood ratio가 supporting / moderate / strong / very strong 각 수준의 기준값을 충족하는 점수 구간을 산출했습니다.
그 결과는, 툴마다 도달 가능한 근거 강도가 다르다.
비교에 사용된 13개 툴 중 Strong 수준까지 도달 가능한 툴은 4개 였습니다. 나머지 9개 툴은 PP3 moderate 또는 supporting 수준에 머물렀고, GERP++는 PP3 supporting조차 충족하지 못했습니다.
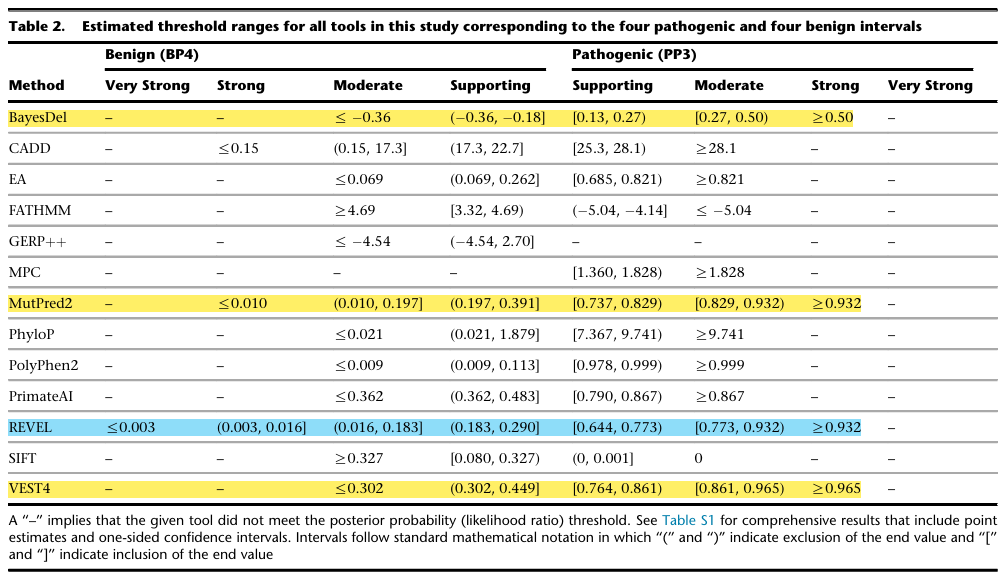
출처: https://pubmed.ncbi.nlm.nih.gov/36413997/
논문은 임상 현장에 이렇게 권고했습니다.
““PP3/BP4 근거 산출을 위해 clinical laboratories는 대부분의 상황에서 단일 툴을 사용하되, pathogenicity 방향으로 strong, benignity 방향으로 moderate 이상을 달성할 수 있는 툴(BayesDel, MutPred2, REVEL, VEST4)을 선택할 것을 권장한다.”
4. REVEL이 왜 권장 기준이 되었는가?
4개의 권장 툴 중에서도 REVEL은 독보적인 위치를 갖습니다.
PP3와 BP4 양방향 모두에서 가장 넓은 스펙트럼을 커버하는 유일한 툴이기 때문입니다.
PP3 strong(≥ 0.932)부터 BP4 very strong(≤ 0.003)까지, 단일 툴로 가장 넓은 evidence strength를 커버합니다.
다만 한 가지 분명히 해 둘 점이 있습니다. REVEL이 이론적으로 BP4 very strong까지 도달할 수 있다는 것과, 그 강도를 실제 판독에 그대로 적용하는 것은 다른 문제입니다. 3billion은 PP3(pathogenic 방향)는 REVEL 점수에 따라 strength를 상향 적용하지만, BP4(benign 방향)는 moderate/strong을 적용하지 않고 supporting까지만 사용합니다. 아직 충분히 규명되지 않은 유전자나 novel variant가 강한 benign 근거 때문에 필터링되어 진단 기회 자체가 사라지는 위험을, 양방향 대칭성보다 우선해 방지하려는 보수적 선택입니다.
또한 REVEL은 다른 툴들의 점수를 통합한 메타 예측 툴이지만, 이 연구에서는 훈련 데이터의 순환 편향(circularity) 문제를 최소화하기 위해 REVEL 및 그 구성 툴들의 훈련 변이를 평가 데이터에서 모두 제거한 후에도 이 성능을 보였습니다 (Materials and Methods, ClinVar 2019 set 구축 방법).
그리고 한 가지 더 — REVEL은 NIH/NCBI에서 배포하는 공공 툴입니다. 독립적인 기관의 검증을 받은 공개 툴이라는 점에서 임상 현장에서의 신뢰 기반이 있습니다.
5. 그렇다면, PP3가 moderate/strong이 된다는 것이 진단에서 무슨 의미인가?
수치가 바뀌었다는 것은 알겠는데, 임상에서 실제로 무슨 차이를 만드는 걸까요.
ACMG/AMP 분류 체계는 각 근거에 points를 부여하고, 합산 점수로 최종 분류를 결정합니다 (Tavtigian et al., 2020).
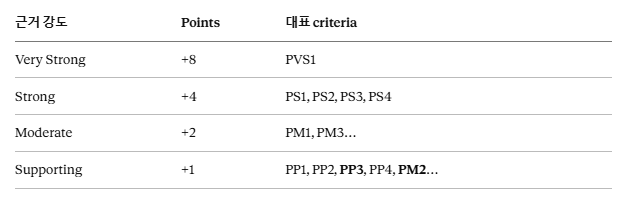
** PM2 적용 강도에 대해: ACMG 2015 원문은 PM2를 moderate(+2)로 정의했습니다. 그러나 gnomAD가 수십만 명 규모로 확장되면서 “gnomAD에 없다”는 희소성의 의미가 크게 약화됐고, 현재 다수의 VCEP는 PM2를 PM2_Supporting(+1)으로 운영하고 있습니다. 3billion도 이 방향을 따릅니다.

LP(Likely Pathogenic) 기준: +6점 이상 / P(Pathogenic) 기준: +10점 이상
기존 PP3는 항상 supporting = +1점 고정이었습니다. 그러나 2022년 ClinGen 권고 이후 REVEL 점수 구간에 따라 PP3는 다음과 같이 달라집니다.

이 차이가 실제 분류를 어떻게 바꾸는지, 시나리오로 보겠습니다.
[시나리오 A] — 기존 방식 (PP3 = 항상 +1)
한 희귀 유전 질환 환자에게서 발견된 missense variant. 아래 근거들이 있습니다.

LP 기준 +6점에 2점 부족. PM2(희귀성)와 PM1(도메인 위치)이 모두 있고 REVEL이 0.95로 매우 높은데도, PP3가 supporting(+1)으로 고정되어 이 변이가 VUS로 남습니다.
[시나리오 B] — ClinGen 2022 권고 적용 (PP3_Strong)

PP3가 supporting에서 strong으로 올라갔는데도, 합계는 +5에서 멈춰 여전히 VUS입니다. PM2가 supporting(+1)이고, 뒤에서 설명할 PM1 중복 제한 때문에 PP3_Strong이 온전한 +4를 발휘하지 못하기 때문입니다. 즉 REVEL 점수를 strong으로 끌어올리는 것만으로는 LP가 되지 않습니다.
여기서 한 가지 중요한 주의사항이 있습니다. PP3_Strong은 이론적으로 +4점이지만, PM1과 함께 사용할 때는 두 criteria의 합산이 strong(+4)을 초과할 수 없습니다. PM1이 이미 +2를 썼다면 PP3_Strong은 +2만 기여할 수 있습니다. 두 기준이 모두 진화적 보존 정보를 부분적으로 공유하기 때문에 double-counting을 막기 위한 장치입니다.
또한 3billion은 실제 판독에서 이 제한을 PM1뿐 아니라 PS1·PM5에도 확장 적용합니다. 다만 그 이유는 PM1과 정확히 같지는 않습니다. PS1(동일 아미노산 변화가 기존에 병원성으로 보고됨)과 PM5(같은 잔기의 다른 변화가 병원성으로 보고됨)는 REVEL의 입력 feature와 중복되는 정보가 아니라, 특정 position에 병원성이 반복적으로 부여되어 있다는 임상 관찰 근거입니다. PP3(예측 점수)와 PS1·PM5가 함께 붙으면 결국 하나의 genomic position에 대한 병원성 신호를 여러 경로로 중복 가산하게 되므로, 이를 strong(+4) 이내로 묶어 과대 가중을 방지하는 것이 3billion의 보수적 내부 정책입니다.
따라서 PP3_Strong이 온전한 +4를 발휘하는 경우는 “PS1, PM5 PM1이 모두 없을 때”입니다.
[시나리오 C] — novel variant에 표현형이 맞아 떨어질 때 (PP3_Strong + PP4)
이번에는 PM1·PS1·PM5가 전혀 없는 novel missense variant입니다. 위치 기반 중복 제한이 걸리지 않으므로 PP3_Strong이 온전한 +4를 발휘합니다. 그래도 PM2가 supporting(+1)이라 PP3_Strong과 합치면 +5, 즉 VUS-high에서 멈춥니다. 여기에 환자의 표현형이 해당 유전자-질환과 매우 특이적으로 일치하면 PP4(+1)를 추가할 수 있고, 그때 비로소 +6으로 LP에 도달합니다.

여기서 분류를 가르는 것은 점수가 아니라 표현형입니다. PP3_Strong이 온전한 +4를 발휘하는 novel variant라 해도, PM2가 supporting인 한 그 자체로는 +5(VUS-high)에 머뭅니다. PP4는 환자의 표현형이 해당 유전자-질환과 충분히 특이적으로 일치할 때에만 적용하는 근거이고, 이것이 더해져야 +6(LP)이 됩니다.
바꿔 말하면 PP3 강도 상향이 의미 있게 VUS를 LP로 끌어올리는 경우는, 임상 증상이 매우 구체적으로 들어맞는 환자에 한정됩니다. 표현형 일치가 없다면 같은 변이는 VUS-high로 남으며, 이는 “기능 연구나 가족 분리분석 같은 추가 근거가 필요하다”는 신호로 다루는 것이 안전합니다. PP4의 적용 여부와 강도는 임상 유전학 전문가가 판단해야 하는 영역입니다.
6. 그러나, REVEL이 가진 한계
REVEL은 강력하지만, 두 가지 대표적 한계가 있습니다.
첫 번째 — 적용 범위의 한계
REVEL은 missense variant에만 적용됩니다. Splice site variant, non-coding regulatory variant, frameshift, stop-gain 등 다른 유형의 변이에는 REVEL 점수 자체가 산출되지 않습니다. 또한 REVEL을 포함한 모든 툴이 26~50%의 변이에서 indeterminate(판단 불가) 구간을 가집니다 (Pejaver et al., 2022, Figure 4B). 즉 REVEL이 답을 내놓지 못하는 변이가 상당수 존재합니다.
두 번째 — ClinVar 기반 학습의 구조적 편향
REVEL은 여러 툴의 점수를 통합한 앙상블 모델입니다. 이 구조에서 비롯된 본질적 한계가 있습니다.
REVEL을 구성하는 툴들 대부분이 ClinVar의 기존 변이 데이터를 학습 기반으로 합니다. 저자들이 학습/평가 데이터를 분리했다고는 하지만, 특정 유전자나 자주 보고되는 변이 패턴이 반복적으로 학습에 반영됐을 가능성은 구조적으로 배제하기 어렵습니다. 결과적으로 REVEL은 ClinVar에 잘 대표된 변이 유형에서는 강하지만, 데이터가 희박한 유전자나 새로운 변이 패턴에서는 예측 신뢰도가 낮아질 수 있습니다.
이는 최근 AlphaMissense나 EVE score처럼 단백질 서열과 진화적 정보만으로 학습한 모델들이 주목받는 이유이기도 합니다. 이들은 ClinVar 레이블에 의존하지 않기 때문에, 기존에 보고된 적 없는 새로운 pathogenic 변이를 발견하는 측면에서 REVEL과 다른 강점을 가집니다.
7. 그래서 3Cnet – 3billion이 개발한 보완 툴
이 간극을 메우기 위해 3billion은 자체 예측 툴 3Cnet을 개발했습니다.
3Cnet은 단순한 앙상블 툴이 아닙니다. Recurrent Neural Network(RNN) 기반의 딥러닝 모델로, 아미노산 서열의 맥락(context)을 직접 학습합니다. 핵심 특징은 다음과 같습니다.
- Multi-task learning: ClinVar의 임상 데이터만이 아니라, gnomAD의 common variant(benign 대리 데이터)와 다종 서열 정렬(MSA) 기반의 진화적 보존 정보를 함께 학습해 과적합을 방지했습니다
- Circularity 회피: 다른 툴들의 점수를 입력으로 사용하지 않아 순환 편향 문제에서 자유롭습니다
- Missense 이외 확장: start lost, stop gain, frameshift 등 non-missense variant에도 적용 가능합니다
성능 비교 (ClinVar August 2020, 외부 검증 데이터셋 기준):
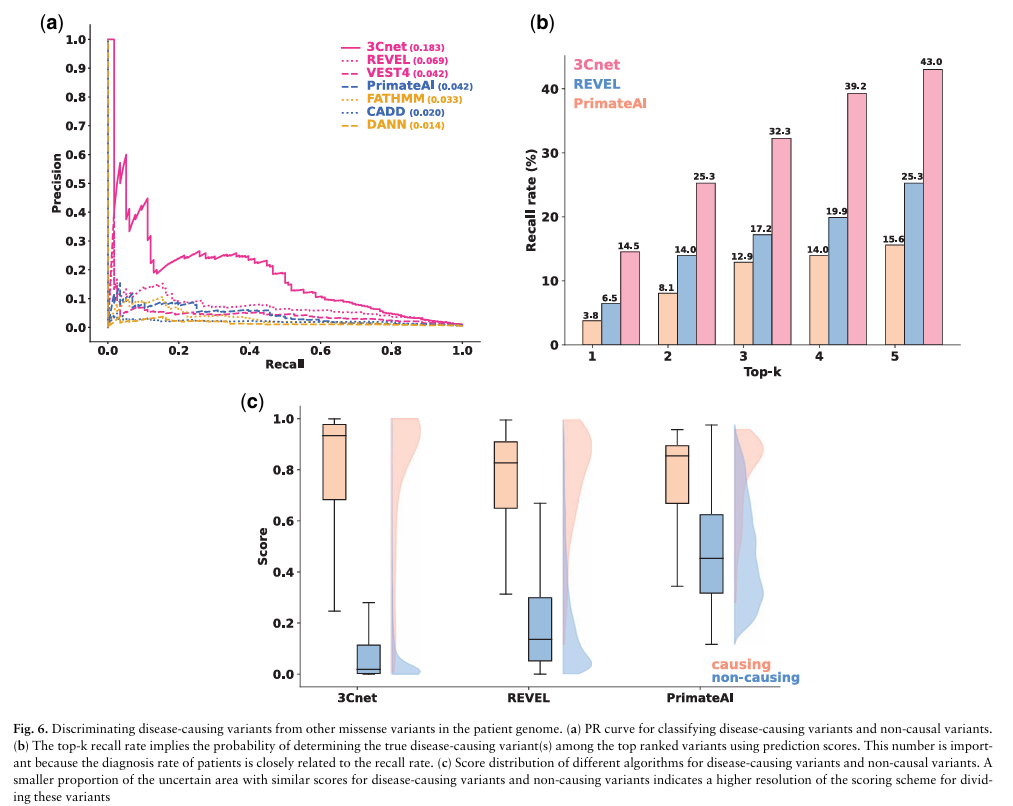
논문의 외부 검증 데이터(6,298개 pathogenic + 6,468개 benign 변이)에서 비교한 ROC-AUC 결과는 다음과 같습니다. 3Cnet은 REVEL보다 높은 ROC-AUC(0.925 vs 0.910)를 보였으며, 평가된 툴 중 가장 높은 성능을 기록했습니다. 더 나아가, 최근에 공개된 3Cnet v2.3 과 v2.5 는 각각 0.946, 0.975 라는 더욱 향상된 ROC-AUC 를 보였습니다.
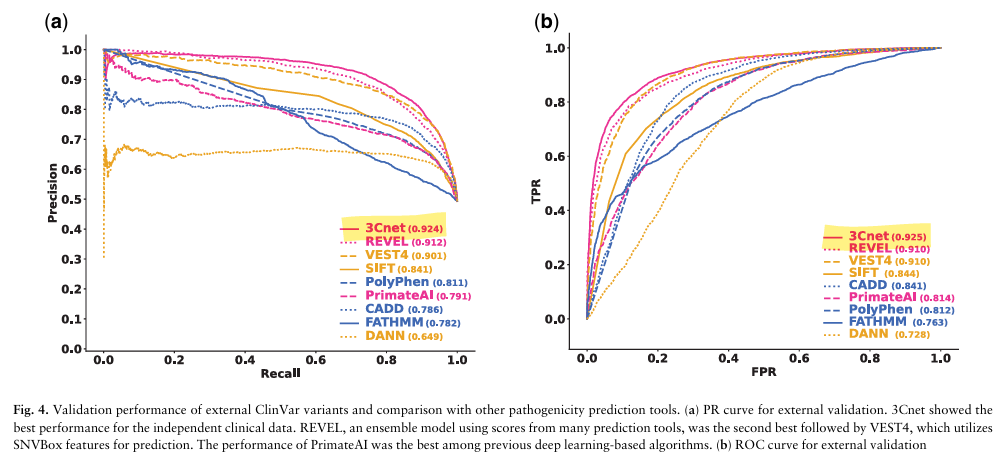
더 임상적으로 의미 있는 지표도 있습니다. 희귀 유전 질환으로 확진된 실제 환자 111명의 게놈에서 질환 유발 변이를 상위 k개 안에 잡아내는 top-k recall 비교에서도, 3Cnet의 top-1 recall은 REVEL의 2.2배였습니다. 환자 1명의 게놈에는 평균 100~400개의 rare missense variant가 존재하는데, 그 중에서 진짜 질환 유발 변이를 상위 1순위로 잡아낼 확률이 약 2배 높다는 의미입니다.
그러나 진단에는 신중함이 필요합니다
3Cnet의 성능 수치는 고무적이지만, 저희가 이 툴을 진단의 1순위가 아닌 보완 도구로 활용하는 이유가 있습니다.
3Cnet 논문의 저자들 스스로도 이렇게 밝히고 있습니다.
“3Cnet은 ClinVar와 gnomAD의 benign 변이를 기반으로 학습했기 때문에 이 편향에서 완전히 자유롭지 않습니다. 해당 데이터베이스에 보고되지 않은 benign 변이를 pathogenic으로 오인할 수 있으므로, benign 변이 식별 시에는 신중한 검증이 필요합니다.” (3Cnet 논문, Discussion)
또한 REVEL은 ClinGen이 공식 권고한 4개 툴 중 하나로, 임상 커뮤니티에서 광범위하게 검증된 근거 기반을 갖추고 있습니다. 진단의 일관성과 재현 가능성 측면에서 REVEL을 1차 기준으로 유지하는 것이 합리적입니다.
8. 3billion의 접근 방식 — REVEL 1차, 3Cnet으로 보완
3billion의 실제 변이 해석 워크플로우는 이렇게 작동합니다.
REVEL을 1차 기준으로, ClinGen 권고 threshold를 적용해 PP3/BP4 근거 강도를 판단합니다. 이를 통해 임상 표준과의 일관성을 유지합니다.
REVEL이 충분한 판단을 제공하지 못하는 경우, 즉 REVEL 점수가 indeterminate 구간에 해당하거나 REVEL이 score를 산출하지 못하는 변이 유형에서 3Cnet을 보조 근거로 활용합니다.
이 접근법의 실제 효과는 3Cnet 논문의 Table 1에서 확인됩니다. REVEL score ≥ 0.75로 이미 높은 점수를 가진 변이를 제외하고, REVEL이 강한 근거를 제공하지 못한 변이들 중 3Cnet score ≥ 0.9인 변이 7건에서 새로운 pathogenic 가능성이 확인됐습니다. 이 중 1건(NP_056651.1: p.Gly54Glu)은 3Cnet의 PP3 근거가 적용됐을 때만 ACMG 분류가 VUS에서 Likely Pathogenic으로 전환될 수 있는 변이였습니다.
희귀 질환 진단에서 단 한 명의 환자에게 내려지는 “VUS”와 “Likely Pathogenic”의 차이는, 그 환자의 치료 방향과 가족 검사 계획을 바꾸는 결정적 차이입니다.
전문가 인터뷰
이 블로그의 주제를 더 깊이 이해하기 위해, 3billion의 임상팀 리더와 3Cnet 개발 리더를 만나 직접 물었습니다.
임상팀 리더 인터뷰 Chief Medical Officer / 서고훈 MD. Ph.D.
Q. 현장에서 PP3의 weight가 달라진 것을 체감하시나요?
” 예전엔 REVEL이 0.95여도 PP3는 supporting 하나라, 다른 근거가 약하면 그대로 VUS였어요. ClinGen 2022 이후엔 PP3가 supporting이 아니라 moderate-strong까지 점수에 잡히게 됐죠. 다만 그게 곧 LP라는 뜻은 아닙니다. PM2를 supporting으로 쓰니까 PP3_Strong을 받아도 대개 VUS-high에서 멈추고, 거기서 더 갈지는 어떤 근거가 같이 있느냐 에 달려 있어요. PS1처럼 이미 강한 근거가 붙은 변이는 의뢰서에 증상이 충분히 안 적혀 와도 보고하지만 — 실제로 그런 경우가 더 많거든요 — 반대로 computational 점수와 희귀성밖에 없는 변이는 결국 임상 표현형이 결정적입니다. 결국 툴이 강해질수록, 어떤 근거에 얼마나 무게를 줄지 판단하는 사람의 역할이 더 커지는 거죠.”
Q. 3Cnet을 실제 케이스에서 어떻게 활용하시나요?
“저희는 REVEL이 먼저고 3Cnet은 두 번째입니다. REVEL이 indeterminate이거나 점수가 애매한 변이에서 3Cnet을 봅니다. 두 툴이 일치하면 그 근거가 더 견고해지고, 엇갈리면 그게 오히려 신중하게 볼 신호가 됩니다. 도구가 하나일 때보다 두 개의 독립적인 관점을 갖는 게 진단의 안전망이 되는 거라고 생각해요.”
3Cnet 개발 리더 인터뷰 Chief Scientific Officer / 이경열 Ph.D.
Q. 3Cnet을 개발할 때 가장 신경 쓴 부분이 무엇이었나요?
“순환 편향(circularity) 문제였습니다. REVEL 같은 메타 예측 툴은 다른 툴들의 점수를 입력으로 씁니다. 그러다 보면 여러 툴이 사실상 같은 정보를 반복해서 보는 셈이 돼요. 3Cnet은 다른 툴의 점수를 전혀 쓰지 않고, 아미노산 서열 자체와 진화적 보존 정보만으로 학습했습니다. REVEL과 3Cnet이 독립적인 관점을 가질 수 있는 이유가 거기에 있습니다.”
Q. 성능 수치가 인상적인데, 임상 적용에서 주의할 점은 무엇인가요?
“논문에서도 직접 썼지만, 3Cnet은 학습 데이터의 편향에서 자유롭지 않습니다. ClinVar와 gnomAD 기반으로 학습했기 때문에, 거기 잘 반영되지 않은 변이 유형이나 특정 민족 집단에서는 성능이 다를 수 있어요. 저희가 3Cnet을 보조 도구로 포지셔닝하는 이유도 그 때문입니다. 높은 3Cnet 점수는 ‘더 자세히 들여다봐야 한다’는 신호이지, 그 자체로 진단을 확정하는 근거는 아닙니다. 그 판단은 임상 유전의가 해야 하는 일이고, 저희 역할은 그 판단을 더 잘 할 수 있도록 좋은 정보를 제공하는 것입니다.”
마치며
PP3와 BP4는 ACMG/AMP 기준 중 AI 기술의 발전이 가장 직접적으로 반영되는 영역입니다. 2022년 ClinGen의 연구는 이 두 기준을 더 이상 단순한 “참고 의견 한 줄”이 아니라, 신뢰할 수 있는 툴에서 충분히 높은 점수가 나올 때는 strong 수준의 근거로 인정받을 수 있다는 근거를 제시했습니다.
그러나 이 글에서 살펴봤듯이, 같은 PP3_Strong 점수라도 어떤 근거와 조합을 이루는지에 따라 최종 분류는 완전히 달라집니다. REVEL 0.95가 나왔다고 해서 LP가 자동으로 결정되는 것이 아니라, PM1이 있는지, PM2만 있는지, 환자의 표현형이 맞는지를 종합적으로 판단해야 합니다. 툴이 점점 강력해질수록, 그 툴의 결과를 임상 맥락 안에서 올바르게 해석하는 전문가의 역할이 오히려 더 중요해집니다.
이것이 임상 유전 진단이 단순한 분석이나 기계적 계산이 아니라는 것을 보여주는 지점입니다. 점수를 산출하는 것과 그 점수의 의미를 해석하는 것은 다른 문제입니다. 3billion이 더 좋은 툴을 개발하고 REVEL과 3Cnet을 함께 활용하는 이유도 결국 같습니다 — 임상 유전의와 유전학자들이 이 전문적 판단에 더 집중할 수 있도록, 그 판단의 재료가 되는 정보를 더 정확하게 제공하는 것. 그것이 3billion이 기술을 쌓아가는 방향입니다.
희귀 유전 질환 진단과 변이 해석에 대해 더 자세한 논의가 필요하시다면 언제든지 문의해 주세요.
참고 문헌
- Pejaver V, et al. Calibration of computational tools for missense variant pathogenicity classification and ClinGen recommendations for PP3/BP4 criteria. Am J Hum Genet. 2022;109(12):2163–2177. https://doi.org/10.1016/j.ajhg.2022.10.013
- Won D-G, Kim D-W, Woo J, Lee K. 3Cnet: pathogenicity prediction of human variants using multitask learning with evolutionary constraints. Bioinformatics. 2021;37(24):4626–4634. https://doi.org/10.1093/bioinformatics/btab529
- Richards S, et al. Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet Med. 2015;17(5):405–424.
https://pubmed.ncbi.nlm.nih.gov/25741868/ - Tavtigian SV, et al. Fitting a naturally scaled point system to the ACMG/AMP variant classification guidelines. Hum Mutat. 2020;41(10):1734–1737. https://doi.org/10.1002/humu.24088
3billion 뉴스레터 구독자만을 위한
희귀질환 진단 최신 정보를 받아보세요.

Sookjin Lee
기술 및 시장 통합 전문가 | 글로벌 헬스케어 혁신 유전체 데이터 기반 의료 분야에서 15년 이상 경력을 쌓은 저는 좋은 기술을 시장 요구에 맞춰 영향력 있는 변화를 만들어내는데 주력하고 있습니다. 전문 지식을 시장 눈높이에 맞춰 전달하고, 새로운 시장으로의 확장을 촉진하여 더 나은 삶을 살게 만들고자 합니다.





