Long-read sequencing compared: PacBio, Oxford , and Illumina
📍Key takeaways
- The real value of long-read sequencing isn’t throughput — it’s the “dead zones.”
- “Long-read” isn’t one thing. PacBio and Oxford Nanopore read long DNA molecules directly — native long-read — while Illumina’s TruPath Genome reconstructs long-range information computationally from short reads. That distinction is what determines how well each platform resolves the hardest regions.
- The options changed in 2026. With TruPath Genome, Illumina has made “long-read–grade information on your existing NovaSeq X, with no new instrument” a reality. That said, it is research-use-only (RUO), and whether it can stand in for native long-read on the most difficult variants is still being established.
- There is no single winner — the right choice depends on the case.

1. Why long-read now? The “dead zone” concept
Sequencing reads out the order of the bases — A, T, G, C — that make up DNA. Because a genome is far too long to read end to end in a single pass, every sequencing method cuts the DNA into manageable pieces, reads those pieces, and stitches them back together computationally. How long those pieces are — the read length — is what separates short-read from long-read sequencing. (More information on Short-read vs. Long read)
- Short-read: reads in short pieces, typically 100–150 bases. It is accurate and inexpensive, which is why it is today’s standard and underlies most exome and whole-genome sequencing.
- Long-read: reads thousands to tens of thousands of bases at a stretch. It costs more, but it reads straight through regions that become ambiguous once they’re chopped into small pieces — repetitive tracts, or genes with near-identical twins. It is often called third-generation sequencing.
Here’s a simple analogy. If you copy a long passage word by word, then whenever the same word shows up in several places you lose track of which sentence each copy came from. Read the whole sentence at once and the position becomes unambiguous. Long-read sequencing is “reading the whole sentence.”
This is where the idea of a dead zone comes in: stretches of the genome that short reads struggle to read or interpret — places dense with repeats, or where nearly identical genes sit side by side. The value of long-read sequencing lies precisely in seeing these dead zones. In undiagnosed rare disease, a recent review concluded that long-read’s added diagnostic contribution clusters in three areas: detecting and interpreting structural variants, sizing repeat expansions, and phasing (along with methylation) (Del Gobbo & Boycott, 2025).
2. Where long-read delivers the “aha” moment

Scenario 1 — Telling apart two look-alike genes (SMA: SMN1/SMN2)
Spinal muscular atrophy (SMA) results from loss of function of the SMN1 gene. The complication is that SMN1 has a near-identical neighbor, SMN2. The two are so alike that short reads often can’t tell whether a variant came from SMN1 or SMN2.
About 95% of SMA patients carry a homozygous deletion that removes both copies of SMN1, which MLPA or exome testing can detect. The remaining ~5%, however, are compound heterozygous — a deletion on one copy and a point mutation on the other — and are easy to miss with conventional tests.
Long-read sequencing brings this into view. In one study, long-read sequencing of a patient with a single SMN1 deletion revealed an additional missense variant in an SMN1 exon, confirming the deletion-plus-point-mutation combination (Wang et al., 2024). Methods built on PacBio HiFi data can resolve full-length SMN1/SMN2 haplotypes and copy number (Paraphase) (Chen et al., 2023), and others have detected SNVs/indels in trans — and even de novo variants — in a single assay (Bai et al., 2023).
Scenario 2 — Measuring the true size of a repeat (DM1)
Myotonic dystrophy type 1 (DM1) is caused by an abnormally expanded “CTG” triplet repeat in the DMPK gene. What matters clinically is that longer repeats mean more severe disease with earlier onset (a phenomenon called anticipation) — so the exact repeat count drives prognosis.
The problem is that short-read and PCR-based methods tend to fall short across long repeat tracts and underestimate their size. So how does long-read get around that limit? One study used amplification-free long-read sequencing to measure DMPK repeats accurately from 130 to more than 1,000 copies, sidestepping the PCR bias that preferentially amplifies shorter repeats (Tsai et al., 2022). Nanopore long-read has also captured repeat length together with interruptions and methylation in a single read-out (Rasmussen et al., 2022). Where short reads tell you that disease is present, long reads add the far more precise question of how severe it is likely to be.
3. How the three work — “native long-read” vs. “computational reconstruction”
The axis that most distinguishes the three platforms isn’t the brand. It’s how each one obtains long-range information.
- PacBio (SMRT/HiFi): records fluorescent signals in real time as an enzyme synthesizes DNA. Reading the same molecule repeatedly produces an error-corrected consensus (CCS); the result — the HiFi read — combines long length with high accuracy.
- Oxford Nanopore (ONT): reads the change in electrical current as a single DNA strand passes through a protein nanopore. Its strengths are ultra-long reads and real-time data generation, and it detects methylation directly.
- Illumina TruPath Genome: unlike the other two, it does not physically read long molecules. On the flow cell, clusters originating from the same source molecule are positioned close to one another, and this proximity-mapped information is used by software (DRAGEN) to reconstruct long-range connections. In short, it aims to obtain long-read–grade distance information from “short reads plus computation.”
4. Comparison
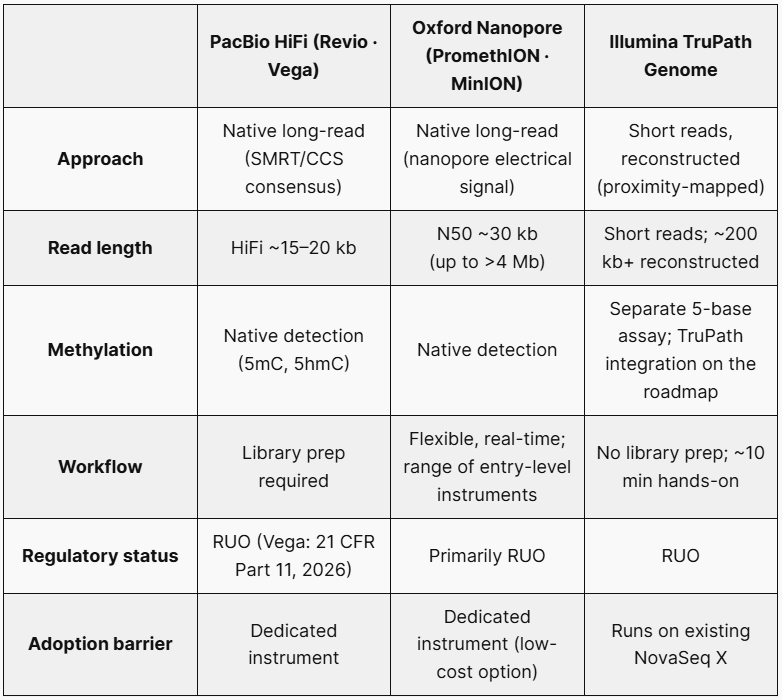
The figures above are approximate ranges drawn from manufacturer announcements and the literature; they vary with chip, chemistry, sample quality, and run configuration. Confirm exact specifications with each manufacturer. It is safest to treat all three as fundamentally research-use-only.
5. Strengths and weaknesses
PacBio HiFi (Revio / Vega)
With HiFi reads that pair long length and high accuracy, PacBio is the platform most often cited for “clinical-grade” human genomes. Its strength is balance — resolving everything from point variants to structural variants, repeats, and phasing accurately in a single run. The latest SPRQ-Nx chemistry reuses SMRT Cells to bring a 20x genome down to roughly $300–345, and methylation (5mC plus 5hmC) comes with every run. The benchtop Vega adds 21 CFR Part 11 features aimed at regulated settings. The main drawback is that it requires a dedicated instrument.
Oxford Nanopore (PromethION / MinION)
Nanopore’s biggest weapon is sheer read length. Ultra-long reads beyond 100 kb help with mapping and with resolving structural-variant and repeat regions. Real-time data generation, suitability for field and rapid diagnostics (such as pathogen identification), and a low barrier to entry with devices like the MinION are further strengths — and it reads methylation directly. Its weakness has been lower raw (single-read) accuracy than HiFi or short reads, though improvements in chemistry and basecalling, together with consensus calling, have narrowed that gap considerably. It is currently regarded as the front-runner in the long-read market across revenue, growth, and financials.
Illumina TruPath Genome
Launched in February 2026, its biggest selling point is obtaining long-range information on an existing NovaSeq X with no new long-read instrument. It eliminates traditional library prep — hands-on time is about 10 minutes — and comes with clear pricing of $395 per sample (consumables plus analysis, ≥30x). Illumina highlights dead-zone resolution, phasing of up to ~98% of genes, and the ability to confirm compound heterozygosity from a single sample without parental samples, with examples such as SMA.
Two things are worth keeping in mind. First, it is research-use-only (RUO) — not a regulatory-cleared clinical test — and its evidence base is largely conference presentations and preprints. Second, because it is fundamentally a “stitch short reads together computationally” approach, whether it can fully replace native long-read on the most difficult structural variants, repeats, and haplotypes is still being established. On the other hand, the “no new instrument” advantage and an enormous installed base are powerful drivers of adoption — which puts it in the interesting position of having its technical limits and its market advantage travel together.
6. So how do you choose?

It is more useful to judge a platform not by “which is best” but by “which fits this patient, this test.”
- When accuracy and clinical-grade genome quality come first (precisely resolving everything from small variants to structural variants and phasing in a single pass): PacBio HiFi.
- When you need ultra-long reads, real-time/field/rapid turnaround, or flexible entry (long repeats, complex structural variants, rapid testing): Oxford Nanopore.
- When you already have NovaSeq X infrastructure and cost, simplicity, and throughput matter (adding long-read–grade information without a new instrument): Illumina TruPath — bearing in mind its RUO status and its limits on the hardest variants.
One positioning note: for patient groups where a dead zone is suspected — repeat-expansion disorders or SMA, for instance — going to long-read from the outset, rather than only as a last resort, can be the more sensible choice in both time and cost, since it reads point variants, structural variants, and repeats all at once.
No need to agonize over which long-read platform is right for you. 3billion handles the entire process — sequencing (performed by an external sequencing partner), analysis, and report delivery. Click the button below to leave your questions about pricing, the process, and anything else.
References
Clinical cases and diagnostic yield
- Del Gobbo GF, Boycott KM. The additional diagnostic yield of long-read sequencing in undiagnosed rare diseases. Genome Research. 2025. https://doi.org/10.1101/gr.279970.124
- Wang N, et al. Diagnosis of Challenging Spinal Muscular Atrophy Cases with Long-Read Sequencing. J Mol Diagn. 2024. https://doi.org/10.1016/j.jmoldx.2024.02.004
- Chen X, et al. Comprehensive SMN1 and SMN2 profiling for spinal muscular atrophy analysis using long-read PacBio HiFi sequencing. Am J Hum Genet. 2023. https://doi.org/10.1016/j.ajhg.2023.01.001
- Bai J, et al. A high-fidelity long-read sequencing-based approach enables accurate and effective genetic diagnosis of spinal muscular atrophy. Clin Chim Acta. 2023. https://doi.org/10.1016/j.cca.2023.117743
- Tsai YC, et al. Identification of a CCG-Enriched Expanded Allele in Patients with Myotonic Dystrophy Type 1 Using Amplification-Free Long-Read Sequencing. J Mol Diagn. 2022. https://doi.org/10.1016/j.jmoldx.2022.08.003
- Rasmussen A, et al. High Resolution Analysis of Hypermethylation and Repeat Interruptions in Myotonic Dystrophy Type 1. Genes (Basel). 2022. https://doi.org/10.3390/genes13060970
- Mortazavi M, et al. Long-read genome sequencing improves detection and functional interpretation of structural and repeat variants in autism. Cell Genomics. 2026. https://doi.org/10.1016/j.xgen.2026.101186
- Chera A, et al. Shedding light on DNA methylation and its clinical implications: the impact of long-read-based nanopore technology. Epigenetics & Chromatin. 2024. https://doi.org/10.1186/s13072-024-00558-2
- Nazarenko MS, et al. Calling and Phasing of Single-Nucleotide and Structural Variants of the LDLR Gene Using Oxford Nanopore MinION. Int J Mol Sci. 2023. https://doi.org/10.3390/ijms24054471
Product and market information
- Illumina. Illumina launches TruPath Genome, setting a new standard in genomic insight (2026-02-24). https://www.illumina.com/company/news-center/press-releases/press-release-details.html?newsid=960974a8-171d-4c27-b2bd-82637ded77b1
- Illumina. Informatics advances reveal the TruPath Genome… (proximity-mapped read , 2026). https://www.illumina.com/science/genomics-research/articles/informatics-advances-reveal-the-trupath-genome-towards-comprehen.html
- PacBio. Revio system (SPRQ-Nx). https://www.pacb.com/revio/
- PacBio. Major Advances for Revio and Vega… (2025-10-14; Vega 21 CFR Part 11). https://www.pacb.com/press_releases/pacbio-announces-major-advances-for-revio-and-vega-to-lower-genome-cost-and-expand-multiomic-capabilities/
- PacBio. Sequencing 101: Comparing long-read sequencing technologies (HiFi vs Nanopore, TruPath). https://www.pacb.com/blog/sequencing-101-comparing-long-read-sequencing-technologies/
- CD Genomics. PacBio vs Oxford Nanopore . https://www.cd-genomics.com/resource-pacbio-oxford-nanopore-comparison.html
- Nanalyze. A Long-Read Duopoly — PacBio or Oxford Nanopore? (2026). https://www.nanalyze.com/2026/01/a-long-read-duopoly-pacbio-or-oxford-nanopore/
Get exclusive rare disease updates
from 3billion.

Soo-jung Baek
As a marketer, I strive to empower the rare disease community by sharing meaningful insights backed by our company’s expertise.





